
Amber's conglomerate corporation just acquired some new companies. Each of the companies follows this hierarchy:

Given the table schemas below, write a query to print the company_code, founder name, total number of lead managers, total number of senior managers, total number of managers, and total number of employees. Order your output by ascending company_code.
Note:
- The tables may contain duplicate records.
- The company_code is string, so the sorting should not be numeric. For example, if the company_codes are C_1, C_2, and C_10, then the ascending company_codes will be C_1, C_10, and C_2.
Input Format
The following tables contain company data:
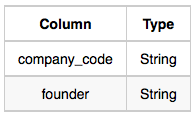

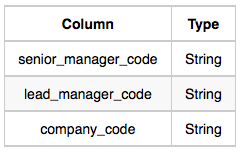
Senior_Manager: The senior_manager_code is the code of the senior manager, the lead_manager_code is the code of its lead manager, and the company_code is the code of the working company.
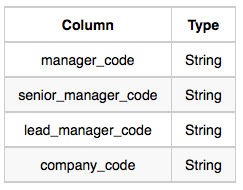
Manager: The manager_code is the code of the manager, the senior_manager_code is the code of its senior manager, the lead_manager_code is the code of its lead manager, and the company_code is the code of the working company.
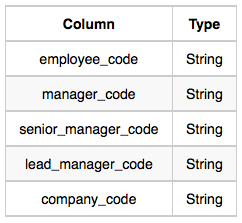
Employee: The employee_code is the code of the employee, the manager_code is the code of its manager, the senior_manager_code is the code of its senior manager, the lead_manager_code is the code of its lead manager, and the company_code is the code of the working company.
Sample Input
Company Table:

Lead_Manager Table:

Senior_Manager Table:

Manager Table:
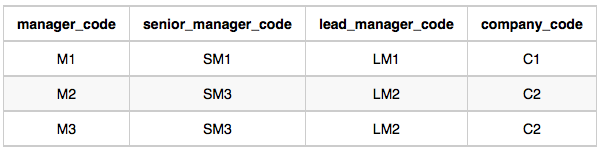
Employee Table:
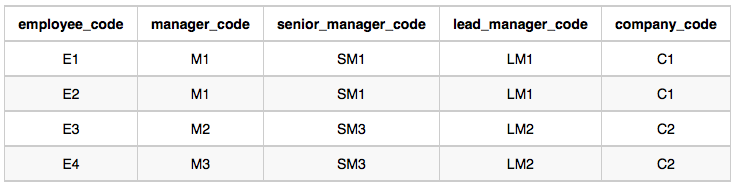
Sample Output
C1 Monika 1 2 1 2
C2 Samantha 1 1 2 2
Explanation
In company C1, the only lead manager is LM1. There are two senior managers, SM1 and SM2, under LM1. There is one manager, M1, under senior manager SM1. There are two employees, E1 and E2, under manager M1.
In company C2, the only lead manager is LM2. There is one senior manager, SM3, under LM2. There are two managers, M2 and M3, under senior manager SM3. There is one employee, E3, under manager M2, and another employee, E4, under manager, M3.
테이블 설명
- Company: 회사의 코드와 설립자 정보를 담고 있습니다.
- Lead_Manager: 리더 매니저의 코드와 그들이 속한 회사의 코드가 있습니다.
- Senior_Manager: 시니어 매니저의 코드, 그들이 속한 리더 매니저의 코드, 그리고 회사 코드가 있습니다.
- Manager: 매니저의 코드, 그들이 속한 시니어 매니저 코드, 리더 매니저 코드, 그리고 회사 코드가 있습니다.
- Employee: 직원의 코드, 그들이 속한 매니저 코드, 시니어 매니저 코드, 리더 매니저 코드, 그리고 회사 코드가 있습니다.
문제 해결 접근법
- 리더 매니저 수 계산: Lead_Manager 테이블에서 회사별로 리더 매니저의 수를 구합니다.
- 시니어 매니저 수 계산: Senior_Manager 테이블에서 회사별로 시니어 매니저의 수를 구합니다.
- 매니저 수 계산: Manager 테이블에서 회사별로 매니저의 수를 구합니다.
- 직원 수 계산: Employee 테이블에서 회사별로 직원의 수를 구합니다.
- 각 쿼리 결과를 회사 코드를 기준으로 조인하여 최종적으로 회사 코드, 설립자 이름, 리더 매니저 수, 시니어 매니저 수, 매니저 수, 직원 수를 출력합니다.
1) 첫 번째 코드
SELECT
c.company_code,
c.founder,
COUNT(DISTINCT lm.lead_manager_code) AS lead_manager_count,
COUNT(DISTINCT sm.senior_manager_code) AS senior_manager_count,
COUNT(DISTINCT m.manager_code) AS manager_count,
COUNT(DISTINCT e.employee_code) AS employee_count
FROM
Company c
LEFT JOIN
Lead_Manager lm ON c.company_code = lm.company_code
LEFT JOIN
Senior_Manager sm ON c.company_code = sm.company_code
LEFT JOIN
Manager m ON c.company_code = m.company_code
LEFT JOIN
Employee e ON c.company_code = e.company_code
GROUP BY
c.company_code, c.founder
ORDER BY
c.company_code ASC;- 장점
- 간결한 쿼리: 한 번에 모든 테이블을 조인하고 그룹화하여 데이터를 처리하기 때문에 구조가 단순합니다.
- 읽기 쉬움: 쿼리의 흐름이 직관적이어서 읽고 이해하기 쉽습니다.
- 유지 보수 용이: 구조가 간단하기 때문에 쿼리를 수정하거나 유지보수할 때 접근이 용이합니다.
- 단점
- 성능 문제: 모든 데이터를 한 번에 조인하고 그룹화하는 방식이기 때문에, 큰 데이터셋의 경우 성능이 떨어질 수 있습니다. 특히, 각 테이블이 큰 경우 쿼리 수행 시간이 길어질 수 있습니다.
- 중복 처리 어려움: 중복 데이터를 처리해야 할 경우, 중복 레코드가 많으면 쿼리가 비효율적일 수 있습니다.
- 메모리 사용: 조인되는 데이터가 많을수록 메모리 사용량이 증가할 수 있습니다.
2) 두 번째 코드
SELECT
c.company_code,
c.founder,
COALESCE(lm.lead_manager_count, 0) AS lead_manager_count,
COALESCE(sm.senior_manager_count, 0) AS senior_manager_count,
COALESCE(m.manager_count, 0) AS manager_count,
COALESCE(e.employee_count, 0) AS employee_count
FROM
Company c
LEFT JOIN
(SELECT company_code, COUNT(DISTINCT lead_manager_code) AS lead_manager_count
FROM Lead_Manager
GROUP BY company_code) lm
ON c.company_code = lm.company_code
LEFT JOIN
(SELECT company_code, COUNT(DISTINCT senior_manager_code) AS senior_manager_count
FROM Senior_Manager
GROUP BY company_code) sm
ON c.company_code = sm.company_code
LEFT JOIN
(SELECT company_code, COUNT(DISTINCT manager_code) AS manager_count
FROM Manager
GROUP BY company_code) m
ON c.company_code = m.company_code
LEFT JOIN
(SELECT company_code, COUNT(DISTINCT employee_code) AS employee_count
FROM Employee
GROUP BY company_code) e
ON c.company_code = e.company_code
ORDER BY
c.company_code ASC;- 장점 :
- 성능 최적화: 각 테이블에서 필요한 데이터만 미리 집계한 후 조인하므로, 대용량 데이터셋에서 더 효율적으로 작동할 수 있습니다. 데이터의 중복이 많을 경우, 서브쿼리를 통해 이를 미리 처리함으로써 메인 쿼리의 부하를 줄일 수 있습니다.
- 유연성: 각 서브쿼리에서 개별적으로 데이터를 처리하기 때문에, 필요한 경우 특정 집계나 필터링을 추가하기가 쉽습니다.
- 쿼리 효율성: 불필요한 조인을 피하고, 필요한 데이터만 조인하기 때문에 실행 속도가 빠를 수 있습니다.
- 단점
- 쿼리의 복잡성: 서브쿼리를 여러 번 사용하기 때문에 쿼리가 다소 복잡해지고, 가독성이 떨어질 수 있습니다.
- 서브쿼리 실행: 각 서브쿼리가 개별적으로 실행되기 때문에, 경우에 따라서는 각 서브쿼리의 실행 비용이 증가할 수 있습니다.
- 잠재적 유지보수 어려움: 서브쿼리가 많아지면 쿼리 구조를 이해하고 유지보수하기 어려워질 수 있습니다.
COALESCE(lm.lead_manager_count, 0) AS lead_manager_count
-- COALESCE 함수는 SQL에서 여러 표현식을 순서대로 평가해 가장 먼저 NULL이 아닌 값을 반환하는 함
-- 조인 결과에서 NULL 값이 발생할 경우 해당 값을 0으로 대체하기 위함
--- 특정 회사가 해당 관리자를 보유하지 않을 경우에도 NULL 대신 0을 반환하도록 하기 위해서
-- JOIN된 테이블에 해당 데이터가 없으면 결과가 NULL이 됨.
--- 예를 들면, 특정 회사에 리드 매니저가 없으면 lm.lead_manager_count가 NULL이 되기 때문에
---- 이 경우 COALESCE를 사용하여 NULL을 0으로 변환

'SQL > HackerRank' 카테고리의 다른 글
| [MySQL/HackerRank] Revising Aggregations - The Sum Function (0) | 2024.08.13 |
|---|---|
| [MySQL/HackerRank] Revising Aggregations - The Count Function (0) | 2024.08.13 |
| [MySQL/HackerRank] Binary Tree Nodes (0) | 2024.08.11 |
| [MySQL/HackerRank] Occupations (0) | 2024.08.11 |
| [MySQL/HackerRank] The PADS (0) | 2024.08.11 |