
파파고 번역 API의 하루 호출 최대량이 10,000자라서 API를 이용한 번역은 어려울 것 같아서 Selenium을 이용해서 진행했다.
텍스트 파일을 불러올 때 보통은 readlines()를 이용해서 불러오는데 이번에는 그냥 read()를 통해서 불러왔다.
with open(txt_files[0], 'r', encoding = 'utf-8') as file:
b = file.read()
한 번에 번역할 수 있는 글자 수가 5,000자라서 나는 4,000자를 기준으로 돌렸다. 텍스트를 길이를 기준으로 자르는 함수를 만들었다.
def split_len(seq, length):
return [seq[i : i+length] for i in range(0, len(seq), length)]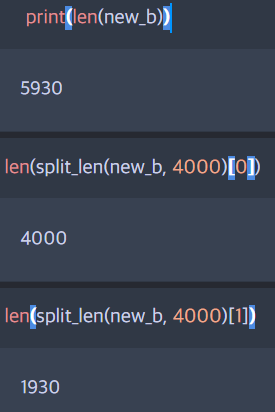
보통은 Selenium을 이용해 값을 전달할 때 driver.find_element_by_xpath(xpath).send_keys()를 이용해서 전달하는데, 나 같은 경우는 한 번에 4000자씩을 보내기 때문에 해당 쿼리를 이용해서 텍스트를 보내면 너무 오래 걸렸다. 그래서 더 빨리 보낼 수 있는 방법을 찾았는데 driver.execute_script('document.getElementById(ID).value="' + message_content + '";') 이렇게 ExecuteScript를 이용하는 방법을 사용했다.
다만 ExecuteScript를 이용해서 텍스트를 보내면 이렇게 화면에 텍스트가 보이지만 글자수로는 반영이 안된 것을 확인할 수 있었다. 그래서 보낸 텍스트를 전체선택 - 복사 - 붙여넣기- 엔터 의 단계를 한 번 더 거치기로 했다.


근데 코드를 완성하고 돌리는데 WebDriverException: Message: unknown error: Runtime.evaluate threw exception: SyntaxError: Invalid or unexpected token
에러가 발생해서 찾아보니까 \n는 ExecuteScript를 할 때 에러가 발생한다고 \\n으로 바꿔서 해보니 잘 실행이 됐다. 근데 이러면 또 문제점이 글자수로 자른 텍스트의 끝 부분이 \으로 끝나면 error가 발생했다.
그래서 글자수로 자르는게 아니라 readlines()로 text를 불러와서 라인별로 자르기를 진행했다.
with open(txt_file, 'r', encoding = 'utf-8') as file:
b = file.readlines()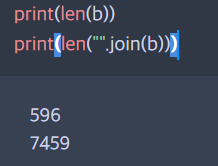
이렇게 불러온 텍스트는 총 596줄, 7459 글자 수를 가지고 있음을 확인했다. 나는 4,000자를 기준으로 자르기로 했으니까 총 글자수를 4,000으로 나눈 몫의 올림을 구하고, 전체 라인 수를 몫의 올림으로 나눠서 진행했다.
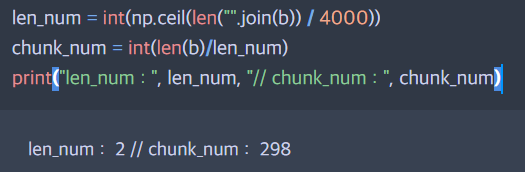
len_num만큼 for문을 돌리고, chunk_num의 길이만큼 list를 잘랐다.
def chunk_list(b, chunk_num):
return [lst[i : i+n ] for i in range(0, len(b), chunk_num)]
from selenium.webdriver.common.keys import Keys
# 전체 선택
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.CONTROL, 'a')
# 복사
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.CONTROL, 'c')
# 붙여넣기
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.CONTROL, 'v')
# 엔터
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.ENTER)
그리고 병음이 필요해서 병음 버튼을 누르고 병음을 가져오는 코드, 그리고 한국어 번역을 가져오는 코드를 작성했다.
# 중국어 병음
driver.find_element_by_xpath('//*[@id="btn-toolbar-source"]/span[3]/span/span/button').send_keys(Keys.ENTER)
# 병음 가져오기
pinyin_text = driver.find_element_by_xpath('//*[@id="root"]/div/div[2]/section/div/div/div[1]/div/div[4]/div/p').text
# 한국어 번역 가져오기
kor_text = driver.find_element_by_xpath('//*[@id="targetEditArea"]').text
txt_files = glob(path)
for txt_file in txt_files :
txtLists = []
txt_file_name = "papago_" + txt_file.split("\\")[1]
# txt 파일 한 줄씩 불러오는 것 확인하기
with open(txt_file, 'r', encoding = 'utf-8') as file:
b = file.readlines()
kor_texts = ""
pinyin_texts = ""
# 4000 글자를 기준으로
len_num = int(np.ceil(len("".join(b)) / 4000))
chunk_num = int(len(b)/len_num)
for i in range(len_num) :
message_content = "".join(chunk_list(b, chunk_num)[i]).replace('"', '').replace("\n", "\\n")
# 텍스트 보내기
driver.execute_script('document.getElementById("txtSource").value="' + message_content + '";')
time.sleep(1.5)
# 전체 선택
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.CONTROL, 'a')
time.sleep(0.5)
# 잘라내기
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.CONTROL, 'c')
time.sleep(0.5)
# 붙여넣기
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.CONTROL, 'v')
time.sleep(0.5)
# 엔터
driver.find_element_by_xpath('//*[@id="txtSource"]').send_keys(Keys.ENTER)
time.sleep(15)
# 중국어 병음
driver.find_element_by_xpath('//*[@id="btn-toolbar-source"]/span[3]/span/span/button').send_keys(Keys.ENTER)
time.sleep(15)
# 병음 가져오기
pinyin_text = driver.find_element_by_xpath('//*[@id="root"]/div/div[2]/section/div/div/div[1]/div/div[4]/div/p').text
pinyin_texts += pinyin_text
time.sleep(3)
# 한국어 번역 가져오기
kor_text = driver.find_element_by_xpath('//*[@id="targetEditArea"]').text
kor_texts += kor_text
time.sleep(2)
# 파파고 새로 로딩
driver.find_element_by_xpath('//*[@id="root"]/div/div[2]/header/div[1]/div/h1/a[1]').click()
time.sleep(1.5)
# List
txtLists.append(["".join(b), kor_texts, pinyin_texts])
pd.DataFrame(txtLists, columns = ['cn', 'kor', 'pinyin']).to_csv("./danmu/papago/" + txt_file_name,
sep = "\t", header = False)일단 중간 완성본! 병음이 \n 단위로 끊어져있어서 문장 단위로 수정중


'python' 카테고리의 다른 글
| 파파고 언어감지 API를 이용해서 중국어만 추출하기 (0) | 2021.07.19 |
|---|---|
| 弹幕(danmu/danmaku) 자막 스크래핑 (0) | 2021.07.19 |