
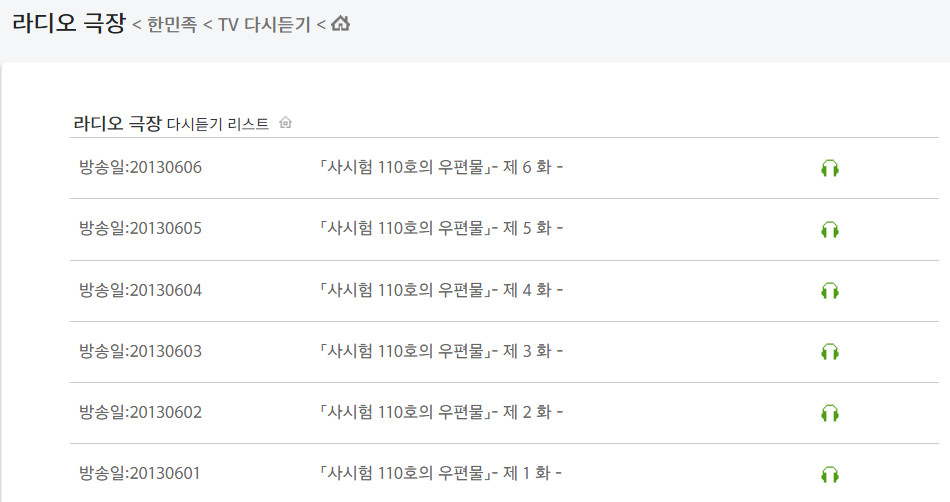
KBS 라디오 극장에서 듣고 싶은 라디오 드라마가 있어서 사이트를 둘러보니 python을 이용해 파일을 저장할 수 있을 것 같았다.
그래서 사이트에서 MP4 주소를 추출하고 저장한 후, MP3로 변환하는 작업을 해보려고 한다.
from selenium import webdriver
import time
import requests
from bs4 import BeautifulSoup
from urllib.request import urlopendriver = webdriver.Chrome("./chromedriver.exe")
webpage = "주소"
driver.get(webpage)# 해당 페이지의 html 소스를 가지고 와서 보기로 함
req = driver.page_source
soup = BeautifulSoup(req, 'lxml')soup.select('#tv3dpFr > div:nth-child(1)')
soup.select('#tv3dpFr > div:nth-child(1) > a')[0]['href']
soup.select('#tv3dpFr > div:nth-child(6) > a')[0].find('img')['alt'].split("_")[0]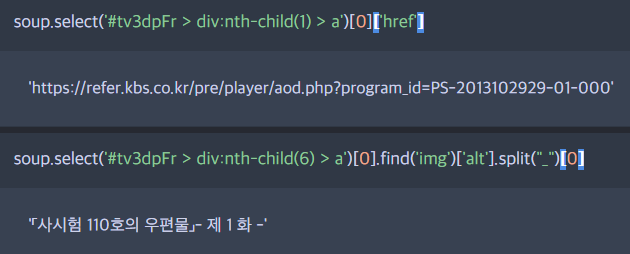
href 정보가 mp4 파일 주소였기 때문에, href를 추출했고
img 태그 속 alt가 해당 회차의 제목 정보를 담고 있었기 때문에 이를 추출해 파일 제목으로 삼기 위해 추출했다.
html = urlopen('https://refer.kbs.co.kr/pre/player/aod.php?program_id=PS-2013098705-01-000')
bs = BeautifulSoup(html, 'html.parser')
bs.select('script')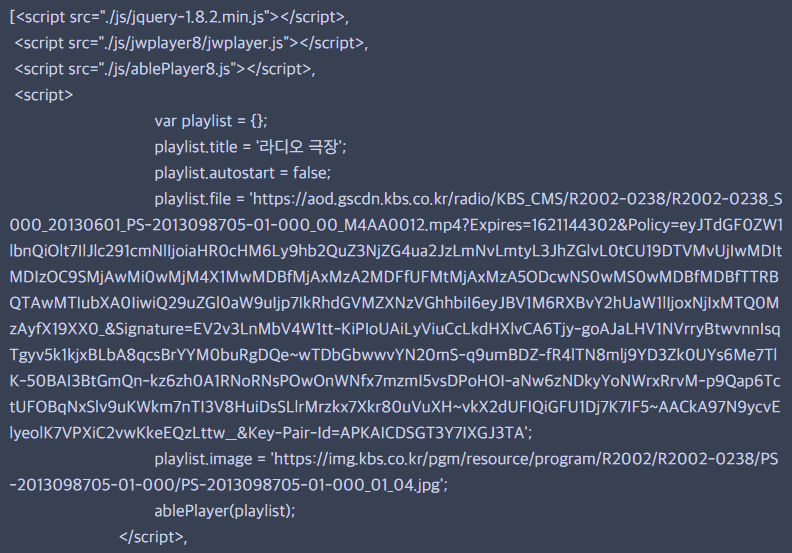
위에서 추출한 각 회차의 영상 주소의 소스를 살펴보니,
<script> </script> 안에 영상 주소가 있기 때문에 Beautiful Soup로 해결이 안되므로, 정규식을 이용해 추출해보기로 했다.
import re
import requests
import jsonurl = "https://refer.kbs.co.kr/pre/player/aod.php?program_id=PS-2013098705-01-000"
page_source = requests.get(url).text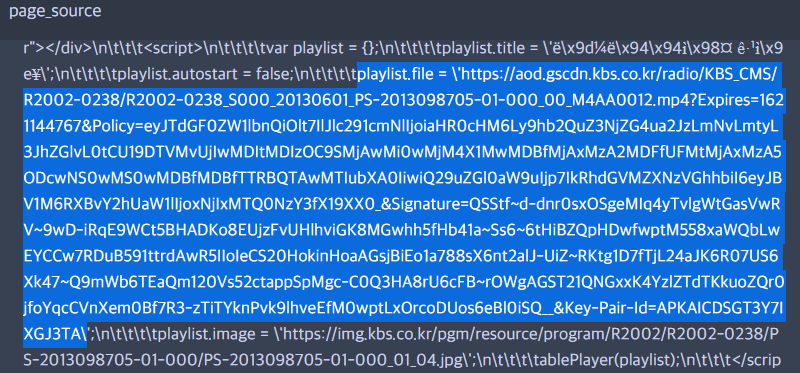
page_source중에서 내가 필요한 부분은 딱 저만큼이고, 저 부분이 추출되도록 정규식을 작성해준다.
mp4_url = re.split('playlist.file = (.+\';)', page_source, re.S)[1].replace(";", "")
mp4_url2 = mp4_url[1:][::-1][1:][::-1]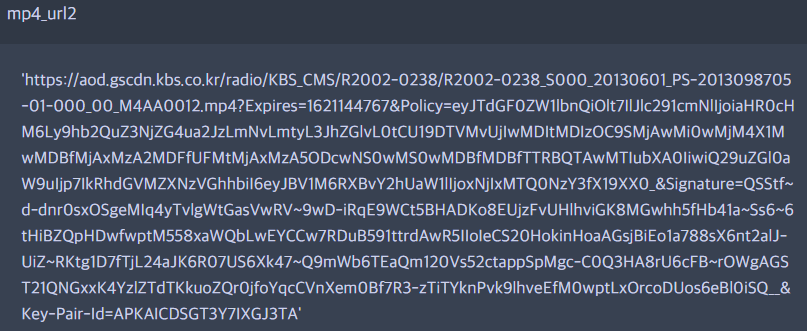
정규식은 해도 해도 어려워서(ㅠㅠ) 간단하게만 추출하고, 앞 뒤로 붙은 "" 같은 경우는 내가 제거해주기로 했다.
import urllib.request
def save_video(video_url, video_name) :
urllib.request.urlretrieve(video_url, video_name)
print("save complete")내가 가져온 주소가 mp4 주소이기 때문에 해당 방법으로 다운이 가능했다.
mp4를 mp3로 변환하는 python 패키지가 있어, 모듈을 설치하고 진행했다.
# pip install moviepy : moviepy 모듈 설치
from moviepy.editor import *
import moviepy.editor as mpclip = mp.VideoFileClip(path)
clip.audio.write_audiofile("audio.mp3")MoviePy error: failed to read the duration of file path. Here are the file infos returned by ffmpeg
해당 에러가 발생해서 여러 방법을 해봤는데, 다른 방법도 KeyError: 'video_fps' 이라는 에러가 발생해서 아예 다른 방법을 사용했다.
https://zulko.github.io/moviepy/ref/ffmpeg.html 해당 사이트에서 새 방법을 찾았다.
mp.ffmpeg_tools.ffmpeg_extract_audio('mp4 저장 위치', 'mp3 저장하려는 위치')

그리고 반복문을 생성해서 다수의 회차의 영상을 다운받고, 변환해보기로 했다.
영상 주소와 회차 정보를 담은 데이터 프레임을 우선 생성하고, 그 데이터 프레임에 담긴 정보로 영상 다운을 진행하도록 했다.
from selenium.webdriver.common.keys import Keys
df_href = []
for i in range(5, 1, -1) :
for list_num in range(1, 11) :
# 현재 페이지의 페이지 소스 다시 받아오기 : 이거 안하면 계속 처음 페이지의 정보만 가져온다
req = driver.page_source
soup = BeautifulSoup(req, 'lxml')
# 해당 페이지에 있는 1 ~ 10까지의 회차 주소와 제목을 가져옴
radio_url = soup.select('#tv3dpFr > div:nth-child(' + str(list_num) + ') > a')[0]['href']
radio_name = soup.select('#tv3dpFr > div:nth-child(' + str(list_num) + ') > a')[0].find('img')['alt'].split("_")[0]
print(radio_name)
# 회차 페이지에서 영상 주소 추출
page_source = requests.get(radio_url).text
mp4_url = re.split('playlist.file = (.+\';)', page_source, re.S)[1].replace(";", "")
mp4_url2 = mp4_url[1:][::-1][1:][::-1] # 추출한 주소 앞 뒤에 "가 붙어있어서 그거 제거하려고
df_href.append([radio_name, mp4_url2])
#print(len(df_href))
time.sleep(1)
# 페이지 넘기기
page_xpath = '//*[@id="navi"]/table/tbody/tr/td[2]/a[' + str(i) +']'
driver.find_element_by_xpath(page_xpath).send_keys(Keys.ENTER)
time.sleep(2)페이지 넘기기를 할 때 .click()이 안되길래 Keys.ENTER를 이용하니 클릭이 되길래 이 방법으로 진행했다.
회차와 영상 주소를 저장할 때, 내가 원하지 않는 정보도 저장이 되었기 때문에 추가로 정제를 해준다.
df_href_final = []
for row in df_href2.itertuples() :
if "사시험" in row.title:
df_href_final.append([row.title, row.href])
#print(row.title)
df_href_final = pd.DataFrame(df_href_final, columns = ['title', 'href'])
# 사서함인데 사시험이라고 되어있어서 이 부분을 수정
df_href_final['title'] = df_href_final['title'].apply(lambda x : x.replace("시", "서").replace("험", "함"))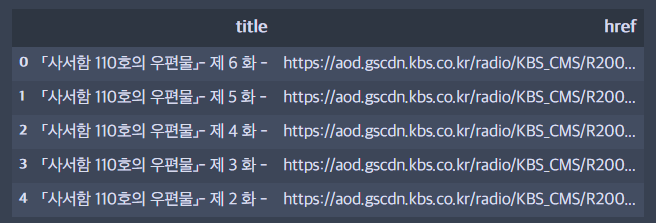
저장된 정보를 이용해서 영상을 다운 받는다.
for row in df_href_final.itertuples() :
save_video(row.href, row.title + ".mp4")
print(row.title)
from glob import glob
mp4_files = glob("파일 경로/*.mp4")
mp4_files # 파일 이름들을 합쳐서 list로 만들어 준 것
그리고 glob을 사용해서 내가 mp4를 저장한 폴더의 모든 mp4 파일의 경로를 가지고 오고,
이 경로를 그대로 반복문에 넣어줘서 mp3 변환을 해보려고 한다.
경로를 설정할 때 "사서함*.mp4"로 하면 사서함으로 시작하고 파일의 형식이 mp4인 파일의 경로가 추출된다.
그리고 저장된 mp4파일을 mp3파일로 변환해준다.
for mp4 in mp4_files :
mp3 = mp4.split(".mp4")[0] + ".mp3"
mp.ffmpeg_tools.ffmpeg_extract_audio(mp4, mp3)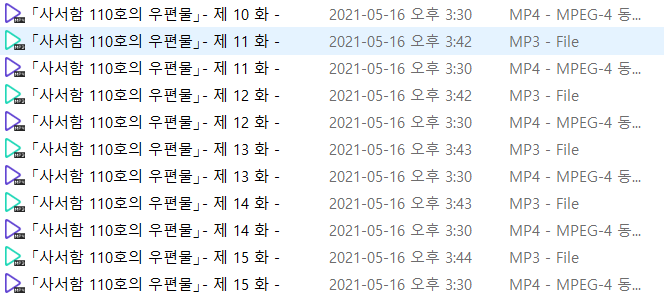
이렇게 잘 변환이 되었다!
다만, 한 파일당 20초 내외의 변환 시간이 걸려서 조금 더 빨리 변환할 수 있는 다른 방법이 있는지 나중에 찾아보려고 한다:)

'python > personal' 카테고리의 다른 글
| chrome elements html로 저장하기 (0) | 2021.07.18 |
|---|---|
| 확장자 없는 파일 뜯어보고, 그 안에 담긴 정보 이용💾 (0) | 2021.07.18 |