
제목을 뭘로 해야할지 모르겠다....
마도조사 드씨를 뒤늦게 알게돼서 부랴부랴 마오얼FM 가입하고 결제를 했다. 예전에는 안드로이드 폰을 사용해서 다운을 받고 파일 디렉토리에 있는 임시 파일의 확장자를 .mp3로만 바꾸면 재생이 된다고 해서 다들 그렇게 소장을 하고 있는 것 같았다. 다만 내가 너무 늦게 알았는지 지금은 단순히 확장자명을 바꾸는 걸로는 안돼서, 혹시 이 파일을 가지고 온전한 파일을 만들 수 있지 않을까 싶어서 파일을 뜯어봤다!

파일의 확장자가 아예 없어서 이게 어떤 파일인지 짐작이 안됐다. 디렉토리명이 sound_blob이라서 blob to mp3, blot to audio 등등 다양한 검색으로 검색을 해봤지만, 방법을 찾지 못했다ㅠ
그러다가 파일을 notepad로 열어보니 m4a 정보가 들어있어서 이걸 활용하면 되겠다! 싶었다.

나는 반복 작업을 싫어하는 인간이니까 이렇게 각 시즌과 화수 그리고 파일명인 ID를 스크래핑해서 데이터 프레임을 만들고, 그 데이터 프레임을 이용해서 파일을 다운받고, 파일명을 정해줘야겠다고 생각했다.


다행히 한 페이지에 시즌당 모든 회차의 정보가 있었다. href와 text 정보만 가져오면 될 것 같았다.
# 최근 열린 탭으로 전환
driver.switch_to.window(driver.window_handles[-1])
# 현재 열린 탭의 페이지 정보
req = driver.page_source
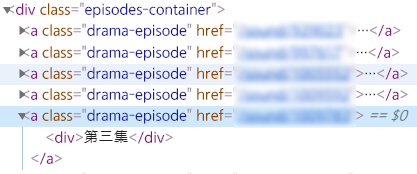
soup = BeautifulSoup(req, 'lxml')시즌이 3개밖에 안돼서 그냥 시즌별 이동은 내가 손으로 해주기로 했다. 다만 새 창으로 열기를 하면 최근 열린 탭으로 전환을 시켜줘야 하고, 그리고 현재 탭의 정보를 새롭게 받아와야 중복으로 받아지지 않는다.
for episode in soup.select(".drama-episode") :
href = episode['href'].split("/")[2]
epi = "第三季 " + episode.text
epi_df.append([epi, href])
그리고 다운 받은 파일들을 어떻게 python에서 불러와서 m4a 정보만 가져올까 요리조리 고민을 하다가, html 파일로 일괄 변경을 한 다음에 BeautifulSoup으로 페이지 정보를 가져오는 방식을 사용했다. text파일로 불러오는게 사실 가장 편한 방법이긴 한데, 자꾸 encoding error가 발생해서 방법을 바꿨다.
import os
files = os.listdir(임시 파일이 저장된 디렉토리)
for file in files:
filename = os.path.join(임시 파일이 저장된 디렉토리) + file
new_filename = os.path.join(html 파일이 저장될 디렉토리) + file
try:
os.rename(filename, new_filename + '.html')
except:
print('error')
passfrom glob import glob
html_files = glob(새로운 html파일이 저장된 디렉토리/*.html)
html_files[:2] # 파일 이름들을 합쳐서 list로 만들어 준 것
# id를 추출하기 위해서
new_html_file = []
for html in html_files :
file = html.split("\\")[1].split(".html")[0]
new_html_file.append([file, html])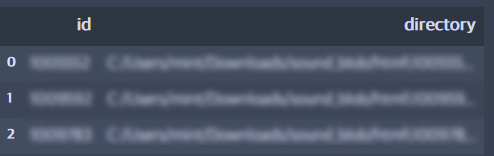
id를 기준으로 pd.merge()를 사용해서 데이터 프레임을 합쳐주면
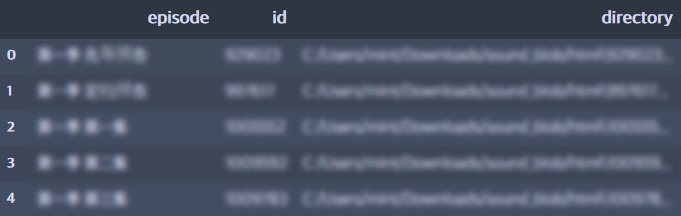
이제 디렉토리에서 html파일을 불러와서, 그 html파일에 담긴 m4a 정보를 새롭게 조작해서 episode 이름으로 다운을 받으면 끝!
href_lists = []
for row in final_df.itertuples() :
direc = row.directory
f = open(direc, 'r', encoding="latin-1")
soup = BeautifulSoup(f, 'html.parser')
test = str(soup).split(".m4a")[0].split("=")[1]
href = "~~~~~~" + test + ".m4a"
href_lists.append([row.episode, row.id, href])
그리고 다운을 받는건, 저번에 라디오 극장 다운 받을 때 사용한 그 방법 그대로를 사용할 수 있어서 좋았다.
import urllib.request
def save_video(video_url, video_name) :
urllib.request.urlretrieve(video_url, video_name)
for row in href_df.itertuples() :
save_video(row.href, row.episode + ".mp3")
print(row.episode)
끝~

'python > personal' 카테고리의 다른 글
| chrome elements html로 저장하기 (0) | 2021.07.18 |
|---|---|
| BeautifulSoup을 이용한 mp4 주소 추출/저장, mp3 변환 (1) | 2021.05.16 |